LINKED LIST
Pengertian Linked List
Linked
List adalah struktur
data yang terdiri dari urutan record data dimana setiap record memiliki
field yang menyimpan alamat/referensi dari record selanjutnya (dalam
urutan). Elemen data yang dihubungkan dengan link pada linked list
disebut Node. Biasanya didalam suatu linked list, terdapat istilah head
dan tail. Head adalah elemen yang berada pada posisi pertama dalam suatu linked list. Tail adalah elemen yang berada pada posisi terakhir dalam suatu linked list.
Terdapat beberapa macam Linked List, yaitu :
- Single Linked List
- Double Linked List
Single Linked List
Single
Linked List merupakan suatu linked list yang hanya memiliki satu
variabel pointer saja. Dimana pointer tersebut menunjuk ke node
selanjutnya. Biasanya field pada tail menunjuk ke NULL.

Operasi Pada Single Linked List
1. Insert = Istilah Insert berarti menambahkan sebuah simpul baru ke dalam suatu linked list.
2. Konstruktor = Fungsi ini membuat sebuah linked list yang baru dan masih kosong.
3. IsEmpty = Fungsi ini menentukan apakah linked list kosong atau tidak.
4. Find First = Fungsi ini mencari elemen pert ama dari linked list
5. Find Next = Fungsi ini mencari elemen sesudah elemen yang ditunjuk now.
6. Retrieve = Fungsi ini mengambil elemen yang ditunjuk oleh now. Elemen tersebut lalu dikembalikan oleh fungsi.
7. Update = Fungsi ini mengubah elemen yang ditunjuk oleh now dengan isi dari sesuatu.
8. Delete Now =
Fungsi ini menghapus elemen yang ditunj uk oleh now. J ika
yang dihapus adalah elemen pertama dari linked list (head), head
akan berpindah ke elemen berikut.
Double Linked List
Double
Linked List merupakan suatu linked list yang memiliki dua variabel
pointer yaitu pointer yang menunjuk ke node selanjutnya dan pointer yang
menunjuk ke node sebelumnya. Setiap head dan tailnya juga menunjuk ke
NULL.

Operasi –operasi pada Double Linked List
- Insert Tail = Fungsi insert tail berguna untuk menambah simpul di belakang (sebelah kanan) pada sebuah linked list.
- Insert Head = Sesuai dengannamanya, fungsi Insert Head berguna untuk menambah simpul di depan (sebelah kiri). Fungsi ini tidak berada jauh dengan fungsi Insert Tail yang t elah dijelaskan sebelumnya.
- Delete Tail = Fungsi Delete Tail berguna untuk menghapus simpul dari belakang. Fungsi ini merupakan kebalikan dari fungsi I nsert Tail yang menambah simpul dibelakang. Fungsi Delete Tail akan mengarahkan Now kepada Tail dan kemudian memanggil fungsi Delete Now.
- Delete Head = Fungsi Delete Head merupakan kebalikan dari fungsi Delete Tail yang menghapus simpul dari belakang, sedangkan Delete Head akan menghapus simpul dari depan (sebelah kiri). Fungsi Delete Head akan mengarahkan Now kepada Head dan kemudianm memanggil fungsi Delete Now.
CIRCULAR DAN NON-CIRCULAR
1. Linked List Circular
Double Linked List
Pengertian secara umumnya DLLC itu Linked list yang menggunakan pointer, dimana setiap node memiliki 3 field, yaitu:
1 field pointer yang menunjuk pointer berikutnya "next",
1 field menunjuk pointer sebelumnya " prev ",
1 field yang berisi data untuk node tersebut .
Double Linked List Circular pointer next dan prev nya menunjuk kedirinya sendiri secara circular. Bentuk Node DLLC
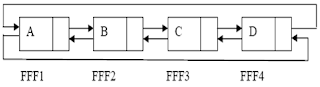
Single Linked List
Single Linked List Circular (SLLC) adalah Single Linked List yang pointer nextnya menunjuk pada dirinya sendiri. Jika Single Linked List tersebut terdiri dari beberapa node, maka pointer next pada node terakhir akan menunjuk ke node terdepannya.

2. Linked List Non Circular
Double Linked List Non Circular (DLLNC)
adalah Double Linked List yang memiliki 2 buah pointer yaitu pointernext dan prev.
Pointer next menunjuk pada node setelahnya dan pointer prev menunjuk pada node sebelumnya.
Pengertian:
Double : artinya field pointer-nya dua buah dan dua arah, ke node sebelum dan sesudahnya.
Linked List : artinya node-node tersebut saling terhubung satu sama lain.
Non Circular : artinya pointer prev dan next-nya akan menunjuk pada NULL.

Single Linked List Non Circular (SLLNC)
Adalah Linked List yang pointer nya selalu mengarah ke Node yang menampung *next bernilai NULL, jadi arahnya tidak menunjuk pointer didepannya sehingga tidak dapat kembali ke pointer - pointer sebelumnya. SLLNC ini juga memiliki 2 bagian, ada Tambah dan ada Hapus, masing - masing bagian ini juga masih meliputi 3 fungsi lain yaitu Belakang, Tengah, dan depan. untuk Contoh Tambah & Hapus (Depan & belakang).

Kita akan sering mengenal kata Push dan Pop. Apa itu Push dan Pop?
1. Push digunakan untuk menambah data.
- PushHead - Menambah data ke barisan paling awal
- PushTail - Menambah data ke barisan paling akhir
- PushMid - Menambah data ke barisan di tengah (sorting)
2. Pop digunakan untuk menghapus data
- PopHead - Menghapus data paling awal
- PopTail - Menghapus data paling akhir
- PopMid - Menghapus data di tengah (sesuai parameter value)
Perbedaan Singly Linked List, Double Linked List, Dan Circular Linked List
- Singly Linked List merupakan suatu linked list yang hanya memiliki satu variabel pointer saja. Dimana pointer tersebut menunjuk ke node selanjutnya, biasanya field pada tail menunjuk ke NULL.
- Doubly Linked List merupakan suatu linked list yang memiliki dua variabel pointer yaitu pointer yang menunjuk ke node selanjutnya dan pointer yang menunjuk ke node sebelumnya. Setiap head dan tailnya juga menunjuk ke NULL.
- Circular Linked List merupakan suatu linked list dimana tail (node terakhir) menunjuk ke head (node pertama). Jadi tidak ada pointer yang menunjuk NULL.
Linked List vs Array
Array :
- kumpulan linear elemen data
- Menyimpan nilai dilokasi memori yang berurutan
- Dapat acak dalam mengakses data
Linked List :
- Kumpulan linear node
- Tidak menyimpan nodenya dilokasi memori yang berurutan
- Dapat diakses hanya secara berurutan
I. Pengertian Stack
Stack atau tumpukan dapat diartikan sebagai suatu kumpulan data yang seolah-olah terlihat seperti ada data yang diletakkan di atas data yang lain. Kaidah utama dalam konsep stack adalah LIFO yang merupakan singkatan dari Last In First Out, artinya adalah data yang terakhir kali dimasukkan atau disimpan, maka data tersebut adalah yang pertama kali akan diakses atau dikeluarkan.




HASH TABLE AND TREE
I. Pengertian
Hash Table adalah sebuah struktur data yang terdiri atas sebuah tabel dan fungsi yang bertujuan untuk memetakan nilai kunci yang unik untuk setiap record (baris) menjadi angka (hash) lokasi record tersebut dalam sebuah tabel.
Keunggulan dari struktur hash table ini adalah waktu aksesnya yang cukup cepat, jika record yang dicari langsung berada pada angka hash lokasi penyimpanannya. Akan tetapi pada kenyataannya sering sekali ditemukan hash table yang record-recordnya mempunyai angka hash yang sama (bertabrakan).
PENGERTIAN





Referensi:
http://tutetutetute.blogspot.com/2010/02/operasi-dasar-stack.html
https://bocahngoding.blogspot.com/2018/01/pengertian-stack-dan-queue-dalam.html
Stack atau tumpukan dapat diartikan sebagai suatu kumpulan data yang seolah-olah terlihat seperti ada data yang diletakkan di atas data yang lain. Kaidah utama dalam konsep stack adalah LIFO yang merupakan singkatan dari Last In First Out, artinya adalah data yang terakhir kali dimasukkan atau disimpan, maka data tersebut adalah yang pertama kali akan diakses atau dikeluarkan.

Sebuah struktur data dari sebuah stack setidaknya harus mengandung dua buah variabel, misalnya variabel top yang akan berguna sebagai penanda bagian atas tumpukan dan array data dari yang akan menyimpan data-data yang dimasukkan ke dalam stack tersebut.
II. Operasi-operasi Dasar Stack
- Operasi push, berfungsi untuk memasukkan sebuah nilai atau data ke dalam stack. Sebelum sebuah nilai atau data dimasukkan ke dalam stack, prosedur ini terlebih dahulu akan menaikkan posisi top satu level ke atas. Berikut ilustrasi kerja pada operasi push :

- Operasi pop, berfungsi untuk mengeluarkan atau menghapus nilai terakhir (yang berada pada posisi paling atas) dari stack, dengan cara menurunkan nilai top satu level ke bawah. Berikut ilustrasi kerja pada operasi pop :

- CREATE(S), berfungsi untuk membuat sebuah stack kosong(menjadi hampa) dan didefinisikan bahwa;
NOEL (CREATE(S)) = 0 dan TOP (CREATE(S)) = null/tidak terdefinisi
- ISEMPTY(S), berfungsi untuk menentukan apakah suatu stack adalah stack kosong(hampa) atau tidak. Operasinya akan bernilai boolean dengan definisi sebagai berikut :
- ISEMPTY(S) = true, jika S adalah stack kosong atau NOEL(S) = 0
- False, jika S bukan stack kosong atau NOEL(S) 0
Catatan : ISEMPTY(CREATE(S)) = true
III. PENGERTIAN QUEUE
Queue atau antrian merupakan struktur data linear dimana penambahan komponen dilakukan disatu ujung, sementara pengurangan dilakukan diujung lain. Kaidah utama dalam konsep queue adalah FIFO yang merupakan singkatan dari First In First Out, artinya adalah data yang pertama kali dimasukkan atau disimpan, maka data tersebut adalah yang pertama kali akan diakses atau dikeluarkan.
Sebuah queue di dalam program komputer dideklarasikan sebagai sebuah tipe bentukan baru. Sebuah struktur data dari sebuah queue setidaknya harus mengandung dua tiga variabel, yakni variabel head yang akan berguna sebagai penanda bagian depan antrian, variabeltail yang akan berguna sebagai penanda bagian belakang antrian danarray dari yang akan menyimpan data-data yang dimasukkan ke dalam queue tersebut.
IV. Operasi-operasi Dasar Queue
- Operasi Enqueue
Operasi push pada antrian disebut juga enqueue. Operasi ini digunakan untuk menambah sebuah elemen baru. Elemen baru akan dimasukkan ke belakang antrian. Algoritma operasi push pada queue adalah sebagai berikut:
- Menentukan kondisi antrian, apakah antrian dalam keadaan kosong atau tidak.
- Jika kosong maka mendeklarasikan data baru yang akan dimasukkan ke dalam antrian.
- Memasukkan nilai data yang baru.
- Melakukan perulangan untuk memasukkan data hingga batas penuh antrian dengan cara menempatkan penunjuk front menunjuk ke elemen terdepan (head) pada antrian dan rear menunjuk ke elemen baru yang ditambahkan dan nilai count bertambah satu .
- Jika antrian sudah penuh maka selesai.
- Operasi Dequeue
Operasi pop pada antrian disebut juga dequeue. Operasi ini digunakan untuk menghapus elemen pada antrian. Elemen yang akan dihapus adalah elemen yang terletak paling depan pada antrian. Algoritma operasi pop pada queue adalah sebagai berikut:
- Melakukan pengecekan kondisi antrian, ada isi data atau tidak.
- Jika terdapat data pada antrian, maka lakukan penghapusan data dengan cara memindahkan head (elemen terdepan antrian) ke elemen setelahnya atau membuat penunjuk front menunjuk ke elemen setelah elemen terdepan pada queue.
- Kemudian menghapus elemen terdepan antrian dan nilai count antrian berkurang satu.
- Jika tidak terdapat data pada antrian maka selesai.
HASH TABLE AND TREE
I. Pengertian
Hash Table adalah sebuah struktur data yang terdiri atas sebuah tabel dan fungsi yang bertujuan untuk memetakan nilai kunci yang unik untuk setiap record (baris) menjadi angka (hash) lokasi record tersebut dalam sebuah tabel.
Keunggulan dari struktur hash table ini adalah waktu aksesnya yang cukup cepat, jika record yang dicari langsung berada pada angka hash lokasi penyimpanannya. Akan tetapi pada kenyataannya sering sekali ditemukan hash table yang record-recordnya mempunyai angka hash yang sama (bertabrakan).
Pemetaan hash function yang digunakan bukanlah pemetaan satusatu, (antara dua record yang tidak sama dapat dibangkitkan angka hash yang sama) maka dapat terjadi bentrokan (collision) dalam penempatan suatu data record. Untuk mengatasi hal ini, maka perlu diterapkan kebijakan resolusi bentrokan (collision resolution policy) untuk menentukan lokasi record dalam tabel. Umumnya kebijakan resolusi bentrokan adalah dengan mencari lokasi tabel yang masih kosong pada lokasi setelah lokasi yang berbentrokan.
II. Operasi pada Hash Table
- insert: diberikan sebuah key dan nilai, insert nilai dalam tabel
- find: diberikan sebuah key, temukan nilai yang berhubungan dengan key
- remove: diberikan sebuah key,temukan nilai yang berhubungan dengan key, kemudian hapus nilai tersebut
- get Iterator: mengambalikan iterator,yang memeriksa nilai satu demi satu
III. Struktur dan Fungsi pada Hash Table
Hash table menggunakan struktur data array asosiatif yang mengasosiasikan record dengan sebuah field kunci unik berupa bilangan (hash) yang merupakan representasi dari record tersebut. Misalnya, terdapat data berupa string yang hendak disimpan dalam sebuah hash table. String tersebut direpresentasikan dalam sebuah field kunci k.
Cara untuk mendapatkan field kunci ini sangatlah beragam, namun hasil akhirnya adalah sebuah bilangan hash yang digunakan untuk menentukan lokasi record. Bilangan hash ini dimasukan ke dalam hash function dan menghasilkan indeks lokasi record dalam tabel.
k(x) = fungsi pembangkit field kunci (1)
h(x) = hash function (2)
Hashing Table pada Blockchain
Hashing berarti mengambil string input dengan panjang berapa pun dan memberikan output dengan panjang tetap . Dalam konteks cryptocurrency seperti Bitcoin, transaksi diambil sebagai input dan dijalankan melalui algoritma hashing (Bitcoin menggunakan SHA-256) yang memberikan output dengan panjang tetap.
TREE
I. Pengertian
Tree merupakan salah satu bentuk struktur data tidak linear yang menggambarkan hubungan yang bersifat hirarkis (hubungan one to many) antara elemen-elemen. Tree bisa didefinisikan sebagai kumpulan simpul/node dengan satu elemen khusus yang disebut Root dan node lainnya terbagi menjadi himpunan-himpunan yang saling tak berhubungan satu sama lainnya (disebut subtree).
I. Pengertian
Tree merupakan salah satu bentuk struktur data tidak linear yang menggambarkan hubungan yang bersifat hirarkis (hubungan one to many) antara elemen-elemen. Tree bisa didefinisikan sebagai kumpulan simpul/node dengan satu elemen khusus yang disebut Root dan node lainnya terbagi menjadi himpunan-himpunan yang saling tak berhubungan satu sama lainnya (disebut subtree).
II. Istilah-istilah pada Tree
a) Prodecessor : node yang berada diatas node tertentu.
b) Successor : node yang berada di bawah node tertentu.
c) Ancestor : seluruh node yang terletak sebelum node tertentu dan terletak pada jalur yang sama.
d) Descendant : seluruh node yang terletak sesudah node tertentu dan terletak pada jalur yang sama.
e) Parent : predecssor satu level di atas suatu node.
f) Child : successor satu level di bawah suatu node.
g) Sibling : node-node yang memiliki parent yang sama dengan suatu node.
h) Subtree : bagian dari tree yang berupa suatu node beserta descendantnya dan memiliki semua karakteristik dari tree tersebut.
i) Size : banyaknya node dalam suatu tree.
j) Height : banyaknya tingkatan/level dalam suatu tree.
k) Root : satu-satunya node khusus dalam tree yang tak punya predecssor.
l) Leaf : node-node dalam tree yang tak memiliki seccessor.
m) Degree : banyaknya child yang dimiliki suatu node.
III. Macam-macam Tree
1. Binary Tree
Binary Tree adalah tree dengan syarat bahwa tiap node hanya boleh memiliki maksimal dua subtree dan kedua subtree tersebut harus terpisah. Sesuai dengan definisi tersebut, maka tiap node dalam binary tree hanya boleh memiliki paling banyak dua child.
Jenis-jenis Binary Tree:
- Perfect Binary Tree
Binary Tree yang tiap nodenya (kecuali leaf) memiliki dua child dan tiap subtree harus mempunyai panjang path yang sama.
- Complete Binary Tree
Mirip dengan Full Binary Tree, namun tiap subtree boleh memiliki panjang path yang berbeda. Node kecuali leaf memiliki 0 atau 2 child.
- Sweked Binary Tree.
Binary Tree yang semua nodenya (kecuali leaf) hanya memiliki satu child.
- Balanced Binary Tree
Binary Tree yang tinggi antara anak sebelah kiri dan kanannya hanya berselisih maksimal satu.
2. Binary Search Tree
Binary Search Tree adalah Binary Tree dengan sifat bahwa semua left child harus lebih kecil daripada right child dan parentnya. Juga semua right child harus lebih besar dari left child serta parentnya. Binary seach tree dibuat untuk mengatasi kelemahan pada binary tree biasa, yaitu kesulitan dalam searching / pencarian node tertentu dalam binary tree.
BINARY SEARCH TREE
PENGERTIAN
Binary Search Tree adalah sebuah konsep penyimpanan data, dimana data disimpan dalam bentuk tree yang setiap node dapat memiliki anak maksimal 2 node. Selain itu, terdapat juga aturan dimana anak kiri dari parent selalu memiliki nilai lebih kecil dari nilai parent dan anak kanan selalu memiliki nilai lebih besar dari parent.
Operasi dasar pada Binary Search Tree :
- Find(x) : menemukan value x didalam BST (Search)
- Insert(x) : memasukan value baru x ke BST (Push)
- Remove(x) : menghapus key x dari BST (Delete)
Ada 3 jenis cara untuk melakukan penelusuran data (traversal) pada Binary Search Tree :
- PreOrder : Print data, telusur ke kiri, telusur ke kanan
- InOrder : Telusur ke kiri, print data, telusur ke kanan
- Post Order : Telusur ke kiri, telusur ke kanan, print data
Operasi : Search
Misalkan mencari value x
- Memulai pencarian dari Root
- Jika Root adalah value yang dicari, maka berhenti
- Jika x lebih kecil dari Root, maka cari ke dalam rekursif tree sebelah kiri
- Jika x lebih besar dari Root, maka cari ke dalam rekursif tree sebelah kanan
Operasi : Insertion
Memasukan value (data) baru kedalam BST dengan rekrusif
Misalkan menginsert value x
- Dimulai dari Root
- Jika x lebih kecil dari node value(key) kemudian cek dengan sub-tree sebelah kiri lakukan pengecekan secara berulang (rekrusif)
- Jika x lebih besar dari node value(key) kemudian cek dengan sub-tree sebelah kanan lakukan pengecekan secara berulang (rekrusif)
- Ulangi sampai menemukan node yang kosong untuk memasukan value x (x akan selalu berada dipaling bawah biasa disebut Leaf atau daun)
Contoh Insertion :




Operasi : Delete (Remove)
- Jika value yang ingin dihapus adalah Leaf (daun) atau paling bawah, langsung delete
- Jika value yang akan dihapus mempunyai satu anak, hapus nodenya dan gabungkan anaknya ke parent value yang dihapus
- Jika value yang akan di hapus adalah node yang memiliki 2 anak, maka ada 2 cara, kita bisa cari dari left sub-tree anak kanan paling terakhir(leaf)(kiri,kanan) atau dengan cari dari right sub tree anak kiri paling terakhir (leaf)(kanan,kiri)
Referensi:
http://rizkiyantikolono.blogspot.com/p/1-penjelasan-dari-linked-list-linked.html
https://oneeio13.blogspot.com/2012/07/pengertian-macam-macam-dan-penggunaan.html
https://www.mahirkoding.com/struktur-data-single-linked-list-dengan-bahasa-c/
http://temanbukuku.blogspot.com/2016/01/operasi-operasi-dasar-single-dan-double.
http://www.mampirlah.com/teknik-informatika/perbedaan-sll-dll-dan-cll.html
http://tutetutetute.blogspot.com/2010/02/operasi-dasar-stack.html
https://bocahngoding.blogspot.com/2018/01/pengertian-stack-dan-queue-dalam.html
http://muqoddasrengmadureh.blogspot.com/2013/01/algoritma-dan-struktur-data-hashing.html
https://sugengsiiswanto.blogspot.com/2014/01/hashing-hash-table-fungsi-hash-struktur.html
http://new-funday.blogspot.com/2012/12/struktur-data-tree-dan-penjelasaanya.html
https://socs.binus.ac.id/2017/05/10/implementasi-insert-pada-binary-search-tree-dengan-single-dan-double-pointer/
https://www.mahirkoding.com/struktur-data-binary-search-tree-bst/
https://abdilahrf.github.io/2015/06/pengenalan-binary-search-tree/
Dibuat oleh :
Livia Leonita
NIM : 2301905726
Class : CB01
NIM : 2301905726
Class : CB01
No comments:
Post a Comment